"Chest X-ray 폐렴 진단 모델"을 kaggle 데이터를 통해 학습 모델을 만드는 과정 중에 만든 모델이 좋은가? 를 평가함에 있어서 서치한 내용을 정리하고자 합니다.
분류 모델의 평가
간단히 말해서 분류 모델의 평가는 아래의 질문으로 정리해보았습니다.
1. "분류를 잘하는가"
2. "모델이 낸 예측과 정답이 같은가"
3. "얼마나가 같은데?"
결국, 내가 만든 모델이 분류를 잘하는지를 알고 싶고, 그렇다면 예측값과 정답이 맞는지 확인해볼 필요가 있으며 최종적으로 얼마나 맞았는지가 이 모델의 성능이나 평가지표가 될 것입니다.
예측값과 정답이 맞는 지를 "Confusion Matrix(혼돈 행렬)"를 통해서 확인할 수 있습니다.

- TP(True Positive) : Positive를 Positive라고 예측한 경우들 (정답)
- FP(False Positive) : Negative를 Positive라고 예측한 경우들 (오답)
- TN(True Negative) : Negative를 Negative라고 예측한 경우들 (정답)
- FN(False Negative) : Positive를 Negative라고 예측한 경우들 (오답)
분류 문제에서 예측한 라벨과 실제 라벨을 배열로 정리한다면 혼동 행렬을 채울 수 있을 것입니다.
이를 통해서 한눈에 모델의 예측값과 정답 관계를 파악할 수 있습니다.
이 표를 통해 최종적으로 모델의 성능을 평가하는 평가지표가 도출됩니다.
분류 모델의 평가지표
그래서, 위에서 정리한 혼돈 행렬을 통해서 주로 우리가 볼 수 있는 지표는 아래와 같습니다.
Chest X-ray 폐렴 진단 모델"을 kaggle 데이터를 통해 학습 모델을 만드는 것을 예시로 작성하겠습니다.
Model이 예측하는 라벨은 "폐렴이 아니다", "폐렴이다", 실제 라벨도 이와 동일할 것입니다.
- 정확도
- 정밀도
- 특이도
- 재현율(민감도)
정확도 (Accuracy)
"전체 개수 중에서 양성과 음성을 맞춘 수"
수식을 보면 혼돈 행렬에 전체 예측한 데이터 중에 정답인 TP, TN의 비율로 구성된 지표입니다.

전체 예측한 데이터중에서 "폐렴이 아니다", "폐렴이다"가 예측값과 실제값이 동일한 정답의 비율을 표기한 것입니다.
가장 직관적이고 보편적인 지표이지만, 데이터의 특성에 따라 지표로 선정에 유의를 기울여야 합니다.
예컨대, "폐렴이 아니다"의 정답이 "폐렴이다"의 정답에 비해 많은 부분을 차지해서 정확도가 높아지는 거라면, 해당 모델에서는 "폐렴인 환자를 폐렴이 아니다(FN)"라고 예측한 오답이 더 중요하게 고려되어야 할 것입니다.
정밀도 (Precision)
"양성이라고 판정한 것 중에 실제 양성 수"
정밀도는 모델이 Positive라고 예측한 것 중에서 정답의 비율, 즉 실제도 Positive인 비율입니다.

True Positive, TP: 모델에 의하여 Positive으로 예측되었고, 실제로도 Positive 인 경우.
False Positive, FP: 모델에 의하여 Positive로 예측되었으나, 실제로는 Negative 인 경우.
Positive라고 예측한 것에 대한 정답률이니, PPV(Positive Predictive Value)라고도 불린답니다.
"폐렴이다"라고 예측한 것들 중에서 "폐렴일 확률"을 표기한 것이죠. 질병을 진단할 때는 정밀도가 굉장히 중요하다고 생각합니다.
참고: 정밀도를 PPV라고 하고 반면에 NPV(Negative Predictive Value) 또는 Fall-out이라는 지표도 있습니다. "음성이라고 판정한 것 중에서 실제 음성 수" 하지만, 주로 고려될 필요가 없죠,,, 모델의 목적이 아닐 가능성이 높으니깐요!
특이도 (Specificity)
"음성 중 맞춘 음성의 수"
특이도는 Negative인 것 중에서 모델이 Negative라고 예측한 비율을 의미합니다.

True Negative, TN: 모델에 의하여 Negative로 예측되었고, 실제로도 Negative 인 경우.
False Positive, FP: 모델에 의하여 Positive로 예측되었으나, 실제로는 Negative 인 경우.
"폐렴이 아니다"라고 예측한 것들 중에서 "폐렴이 아닐 확률"을 표기한 것이죠.
제가 예시로 든 질병 진단, 폐렴 진단 모델의 경우는 정확도보다는 정밀도와 특이도를 파악하는 것이 더 중요한 지표라고 생각합니다.
재현율 (Recall, Sensitivitiy)
"양성 중 맞춘 양성의 수"
재현율은 Positive인 것 중에서 모델이 Positive라고 예측한 비율을 의미합니다.

True Positive, TP: 모델에 의하여 Positive으로 예측되었고, 실제로도 Positive 인 경우.
False Negative, FN: 모델에 의하여 Negative로 예측되었으나, 실제로는 Positive 인 경우.
정밀도, 재현율의 Trade-off 관계
이 관계에 대해 알아보기 전에 비슷한 개념은 "가설 검정"에서 "Type 1 error", "Type 2 error"가 있습니다.
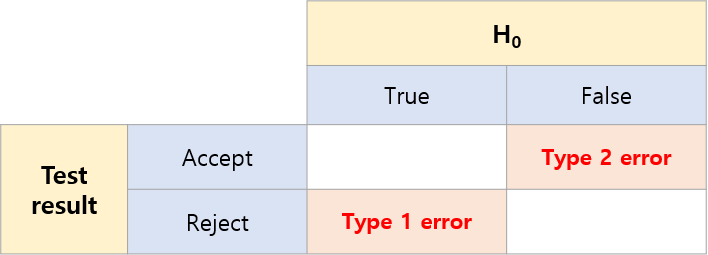
가설 검정 표를 혼돈 행렬과 같이 비교해본다면, 다음과 같을 것입니다.
H0 True : 모델이 Positive로 예상한 경우 (이 가설은 맞을 거야!)
H0 False : 모델이 Negative로 예상한 경우 (이 가설은 아닐 거야!)
Test result Accept : 실제 값이 Positive인 경우 (실제로 너의 가설이 맞아!)
Test result reject : 실제 값이 Negative인 경우 (실제로 너의 가설은 아니었어!)
Type 1 error는 모델이 Positive로 예상했지만 Negative인 경우, 즉 FP
Type 2 error는 모델이 Negative로 예상했지만 positive인 경우, 즉 FN
가설 검정 시에 어떤 상황에서 어떤 가설을 받아들일지의 기준이 필요하고, 그 기준이 "Any mean"을 어디로 설정할 지에 따라 "Type 1 error"와 "Type 2 error"는 Trade-off 관계를 가지게 됩니다.
여기서 "Any mean"이 정해지는 것이 Threshold 선정이라고 불립니다.
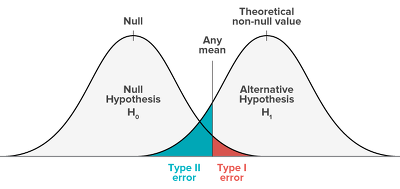
본론으로 돌아와서 정밀도와 재현율 이와 동일합니다.
위의 그래프를 "폐렴 진단 모델"에 대한 혼돈 행렬의 TN, TP, FN, FP로 표현해보면 아래와 같습니다.
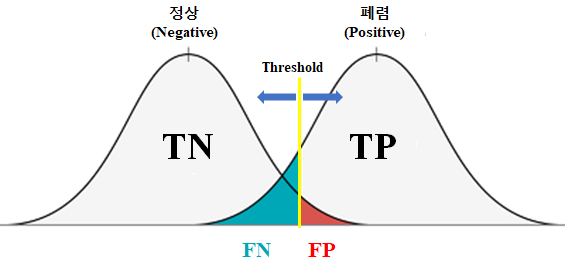
이해가 되실까요?? 재현율과 정밀도를 구성하는 수식에서 "FN"과 "FP"로 다르고, 둘 다 분모에 위치하기 때문에
해당 모델에서 "Threshold"를 좌우로 이동하면 정함에 따라서 FN과 FP는 Trade-off 관계를 가질 수밖에 없고, 이는 정밀도와 재현율이 Trade off 관계를 이룰 수밖에 없게 됩니다.
이 특성 때문에 재현율과 정밀도는 서로 보완적인 지표로 분류 모델의 성능을 평가하는데 적용되며, 둘 다 높은 수치를 얻는 것이 가장 좋은 성능을 의미한다. 반면 둘 중 어느 한 평가 지표만 매우 높고, 다른 하나는 매우 낮은 결과를 보이는 것은 바람직하지 않다.
그래서, Threshold는 어떻게 선정해야 할까요?
정밀도와 재현율이 왜 Trade-off 관계를 가질 수밖에 없는지 알았는데요! 그러면 둘 다 좋을 수 있는 최적의 Threshold를 선정하는 것이 좋을 것이고 이것은 어떻게 해야 할까요?
"결론적으로 목적에 따라 다릅니다. "
- 재현율이 상대적으로 더 중요한 지표인 경우는 실제 Positive 양성인 데이터 예측을 Negative 음성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우
- 재현율이 중요 지표인 경우는 암 판단 모델이나 금융 사기 적발 모델과 같이 실제 Positive 양성 데이터를 Negative로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우
- 정밀도가 상대적으로 더 중요한 지표인 경우는 실제 Negative 음성인 데이터 예측을 Positive 양성으로 잘못 판단하게 되면 업무상 큰 영향이 발생하는 경우
- 스팸메일 여부를 판단하는 모델과 같은 경우는 정밀도가 더 중요한 경우
'AI Study' 카테고리의 다른 글
| [AI Study] R-CNN 시리즈 훑어 보기 (0) | 2022.01.05 |
|---|---|
| [AI Study] Object Detection 1-stage vs 2-stage (0) | 2022.01.04 |
| [AI Study] 오토인코더 (autoencoders)란? (0) | 2021.07.16 |
| [AI Study] Confusion Matrix를 통한 모델 성능 평가하기 (0) | 2021.07.06 |
| [머신러닝] 나이브 베이즈 (0) | 2021.06.22 |
