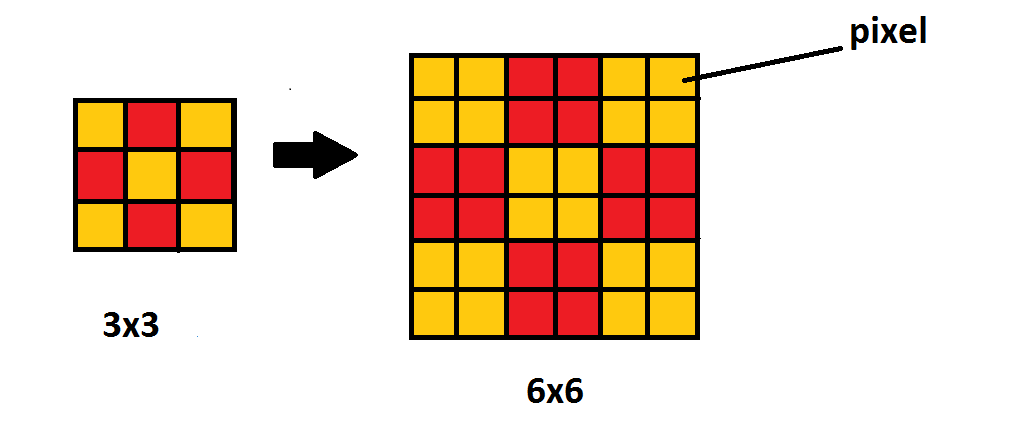
<Introduction>
본 포스트에서느 이미지 처리 중 "밝기조절" 과 "대조도"에 대해 알아보고 구현해보고자 합니다.
<Luminosity>
명도라고도 불리는 밝기는 이미지의 픽셀 값에 사용자가 설정하여 입력할 밝기도를 정하여 픽셀값에 더해주면 됩니다.
픽셀의 값이 증가하면, 이미지가 밝아집니다. 반면에 픽셀의 값이 감소하면 어둬어집니다.
$$ LuminosityImageValue = ImageValue + LuminosityValue $$
간단하게 이미지의 픽셀을 불러와서 명도 수치를 더해주면 됩니다!
<Luminosity - 구현>
from PIL import Image, ImageDraw
# 설정하고자 하는 밝기도
luminosity = 80
# 이미지 로드
input_image = Image.open("input.png")
input_pixels = input_image.load()
# 출력 이미지 생성
output_image = Image.new("RGB", input_image.size)
draw = ImageDraw.Draw(output_image)
# 이미지의 픽셀에 밝기도 더하여 출력
for x in range(output_image.width):
for y in range(output_image.height):
r, g, b = input_pixels[x, y]
r = int(r + luminosity)
g = int(g + luminosity)
b = int(b + luminosity)
draw.point((x, y), (r, g, b))
output_image.save("output.png")
<Contrast 대조도>
Contrast는 이미지의 밝은 부분과 어두운 부분의 차이를 의미하고, 이를 조절한다는 것은 이미지의 밝은 부분과 어두운부분의 차이를 조절한다는 의미입니다. 이는 이미지내의 물체를 선명하게 보는 효과를 가지고 옵니다.
예를들어, 이미지 안의 픽셀들이 대부분은 비슷한 Intensity(값)을 가진다면 어떨까요?
이미지는 아래와 같이 어떠한 물체 정보도 얻기 힘들 것입니다.

이 경우를 대조도가 낮다 라고 말할 수 있습니다. 반면에, 대조도가 높다는 것은 이미지 내의 물체를 식별하는데 용이하고 이는 선명하다 라는 느낌을 주게됩니다.
<Contrast 대조도 - 구현>
앞서 말씀드린 것처럼 대조도가 높다는 것은 이미지 내의 물체를 식별하는데 용이하고, 선명하다 라는 느낌을 주게됩니다. 즉, 대개는 대조도를 높여 이미지를 선명하게 하는 것이 이미지의 질을 높이는 방향일 것입니다.
어떻게 대조도를 만드느냐에 대해는 여러가지 방법론이 있습니다. 하지만 핵심은 "intensity 값의 곱" 입니다.
즉, 입력이미지의 픽셀에 어떠한 조정 값을 곱하여 대조도를 변경 할 수 있습니다.
예를 들어, A라는 픽셀은 100이라는 Intensity를 가지고, B라는 픽셀은 50이라는 intenstiy를 가진다고 가정합니다.
Contrast를 높이기 위해 두 픽셀 값에 대해 1.5를 곱한다고 하면, A= 150, B=75가 됩니다.
1.5를 곱하기 전의 A-B의 값은 50이였지만, 1.5를 곱한 후의 A-B의 값은 75입니다.
즉, 두 픽셀의 값의 차이가 더 벌어진 것입니다. 이러한 원리로 대조도를 조정합니다.
이때 곱해지는 값을 정하는 방법은 여러가지가 있습니다.
from PIL import Image, ImageDraw
# Load image:
input_image = Image.open("input.png")
input_pixels = input_image.load()
# Create output image
output_image = Image.new("RGB", input_image.size)
draw = ImageDraw.Draw(output_image)
# Find minimum and maximum luminosity
imin = 255
imax = 0
for x in range(input_image.width):
for y in range(input_image.height):
r, g, b = input_pixels[x, y]
i = (r + g + b) / 3
imin = min(imin, i)
imax = max(imax, i)
# Generate image
for x in range(output_image.width):
for y in range(output_image.height):
r, g, b = input_pixels[x, y]
# Current luminosity
i = (r + g + b) / 3
# New luminosity
ip = 255 * (i - imin) / (imax - imin)
r = int(r * ip / i)
g = int(g * ip / i)
b = int(b * ip / i)
draw.point((x, y), (r, g, b))
output_image.save("output.png")

'영상처리' 카테고리의 다른 글
| [영상처리] Image Flip (python 직접구현) (0) | 2022.01.21 |
|---|---|
| [영상처리] Image Scale (python 직접구현) (0) | 2022.01.20 |
| [영상처리] 이미지 색상 표현 (0) | 2022.01.19 |
| [영상처리] Image Cropping (python 직접 구현) (0) | 2022.01.18 |
| [영상처리] Grayscale image 만들기 (python 직접구현) (0) | 2022.01.17 |