
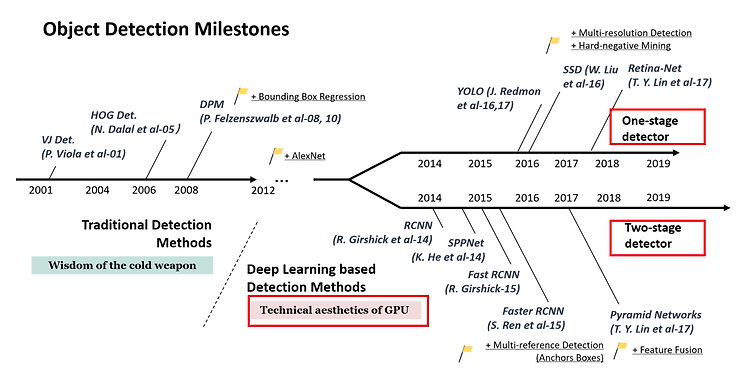
<Introduction>
객체 검출 문제에서 이미지 내에서 사물을 인식하는 방법에는 다양한 유형이 존재합니다.
객체 검출 문제는 다수의 사물이 존재하는 이미지나 상황에서 "각 사물의 위치를 파악하고 사물을 분류" 하는 작업입니다.

위 그림을 하나씩 보도록 합시다.
1. Classification: 전통적인 분류 문제는 하나의 이미지를 입력을 받아 해당 이미지가 어떤 클래스인지를 맞추는 문제
2. Classification + Localization: 전통적인 분류를 거치고 나아가 해당 클래스가 존재하는 위치까지 찾는 문제
3. Object Detection: 한 이미지에 다수의 사물이 존재하여 다수의 사물의 위치와 클래스를 찾는 문제
4. Instance Segmentation: 각각의 사물 객체를 픽셀 단위로 다수의 사물의 클래스와 위치를 실제 edge로 찾는 문제
모두 사물을 인식하는 방법에 대한 유형이 되고, Object Detection에서 사용되는 모델 중 하나인 "R-CNN", "Fast R-CNN", "Faster R-CNN"에 대하여 간략히 리뷰하겠습니다.
<R-CNN>
R-CNN은 대표적인 2-stage 방식의 알고리즘 모델이며, Regional Proposal 단계에서 Selective search 방식을 적용하여 2000개의 window를 사용하였습니다.

위 그림을 단계별로 살펴 보겠습니다.
1. 입력 이미지를 받아, "CPU" 상에서 Selective search 방식을 사용하여 약 2000개의 영역을 추출합니다.
2. 추출된 약 2000개의 영역의 이미지를 모두 동일한 input size로 만들기 위해 이미지 crop과 resize을 진행합니다.
3. 2000개의 warped image를 각각 CNN 모델에 입력하여 피처를 추출합니다.
4. 피처 맵을 이용해서 SVM에서는 클래스를, Regressor에서는 클래스의 위치를 bounding box로 찾아냅니다.
특징
1. regional proposal 단계에서 추출한 2000개 영역을 CNN모델에 학습을 해야 합니다.
즉, CNN * 2000 만큼의 시간이 소요되어 수행 시간이 길어집니다.
2. CNN, SVM, Bounding Box Regression 총 세 가지의 모델이 한 번에 학습되지 않지 않습니다.
즉, 학습한 결과가 Bounding Box Regression은 CNN을 거치기 전의 region proposal 데이터가 입력으로 들어가고, SVM은 CNN을 거친 후의 feature map이 입력으로 들어가기 때문에 연산을 공유하지 않고, 그렇기 때문에 end-to-end로 학습할 수 없습니다.
<Fast R-CNN>
Fast R-CNN은 R-CNN이 가지는 단점을 극복한 모델로
1) ROI Max pooling,
2) 영역의 특징 추출을 위한 CNN 모델부터 클래스와 클래스 위치를 찾는 연산까지 하나의 모델에서 학습이 가능하도록 하였습니다. 즉, R-CNN에서 CNN * 2000 만큼의 시간을 CNN * 1 만큼의 시간이 걸리게 되었습니다.

위 그림을 단계별로 살펴보겠습니다.
1. 입력 이미지를 받아, "CPU" 상에서 Selective search 방식을 사용하여 약 2000개의 영역을 추출합니다.
2. 추출된 약 2000개의 영역의 이미지를 모두 동일한 input size로 만들기 위해 이미지 crop만 진행합니다.
3. 입력 이미지를 CNN에 통과시켜 feature map을 추출합니다.
4. 추출된 약 2000개의 영역을 앞서 추출한 feature map에 projection 시킵니다.
5. 추출된 약 2000개의 영역이 projection 된 feature map을 각 ROI에 대한 Pooling을 진행하여 feature vector를 추출합니다.
6. 이 feature vector는 FC layers를 지나서 클래스를 분류하는 "softmax"와 클래스가 있는 bounding box를 찾는 regressor에 각각 입력되고 연산을 거쳐 결과를 도출합니다.
특징
1. R-CNN에서 2000개의 영역에 대한 CNN을 수행하여 시간 소요가 길었지만, ROI pooling을 진행하여 CNN연산을 1번으로 줄었습니다.
즉, CNN * 1 만큼만 시간이 소요되어 수행 시간이 줄었습니다.
2. R-CNN에서 SVM과 regressor가 입력을 공유하지 않기 때문에 "end-to-end" 방식으로 진행하기 어려웠으나, 이를 ROI pooling을 진행함으로써 ROI의 영역을 CNN을 거친 후에 feature map으로 projection 시킬 수 있었습니다.
즉, Bounding Box Regression와, 클래스 분류의 softmax에 CNN을 거친 후의 feature map이 동일한 입력으로 들어가기 때문에 연산을 공유하고, 그렇기 때문에 end-to-end로 학습할 수 있습니다.
3. Fast R-CNN이 R-CNN에 비해 성능과 시간을 효과적으로 향상했으나, 여전히 Region proposal 단계에서 Selective search 알고리즘을 "CPU"상에서 진행되므로 이 부분이 시간이 소요된다는 점이 단점으로 남아있었습니다.
<Faster R-CNN>
Faster R-CNN은 Fast R-CNN이 가지는 단점을 극복한 모델하기 위해 RPN(Region Proposal Network)를 1-stage 단계에서 제안한 방법입니다.
즉, Faster R-CNN의 아이디어는
"Fast R-CNN의 1-stage 단계에서 Region Proposal 방법으로 Selective search이 "CPU" 상에서 진행되니깐, "GPU"를 사용할 수 있도록 Region Proposal 자체도 네트워크를 적용해서 진행해보자!"입니다.
그렇기 때문에 Faster R-CNN은 한마디로 RPN + Fast R-CNN이라 할 수 있으며, Faster R-CNN은 Fast R-CNN구조에서 conv feature map과 RoI Pooling사이에 RoI를 생성하는 Region Proposal Network가 추가된 구조가 되겠습니다.

1. 입력 이미지를 받아, "GPU" 상에서 RPN 네트워크를 사용하여 영역을 추출합니다.
2. RPN 네트워크에서 사물이 있을 법한 영역과 위치를 추출합니다. ("사물이 있다", "사물이 없다" -> 2 softmax)
3. feature map을 각 ROI에 대한 Pooling을 진행하여 feature vector를 추출합니다.
4. 이 feature vector는 FC layers를 지나서 클래스를 분류하는 "softmax"와 클래스가 있는 bounding box를 찾는 regressor에 각각 입력되고 연산을 거쳐 결과를 도출합니다.
차후에 각 R-CNN에 대해 특히나 Faster R-CNN에 대해 상세하게 다루어 보겠습니다.
<R-CNN 시리즈 요약>

<참고 자료>
https://medium.com/zylapp/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
Review of Deep Learning Algorithms for Object Detection
Why object detection instead of image classification?
medium.com
https://www.arxiv-vanity.com/papers/1908.03673/
Recent Advances in Deep Learning for Object Detection
Object detection is a fundamental visual recognition problem in computer vision and has been widely studied in the past decades. Visual object detection aims to find objects of certain target classes with precise localization in a given image and assign ea
www.arxiv-vanity.com
'AI Study' 카테고리의 다른 글
| [AI Study] Roboflow 탐험하기(1) - 시작, 무료 데이터셋 접근 (0) | 2022.01.20 |
|---|---|
| [AI Study] 활성화 함수가 비선형성이 필요한 이유 (0) | 2022.01.19 |
| [AI Study] Object Detection 1-stage vs 2-stage (0) | 2022.01.04 |
| [AI Study] 머신러닝 분류모델 성능 평가 지표 정리 (정밀도, 재현율, 정확도) (0) | 2021.12.31 |
| [AI Study] 오토인코더 (autoencoders)란? (0) | 2021.07.16 |





