00. 서문
오토 인코더에 대해서 공부해야 할 일이 생겨서, 하는 도중 정리하기 위해 포스팅을 하게 되었습니다.
공부하여 작성하는 거라, 부족할 수 있으니 많은 피드백 주시면 감사하겠습니다.
01. 오토 인코더 (autoencoder)
오토 인코더는 비지도 학습 방법의 하나입니다. 그러기 때문에 모델을 학습하기 위한 명확한 라벨(정답)이 제공되지 않습니다. 즉, 오토 인코더를 학습하기 위해서는 입력 데이터를 필요로 합니다.
제가 공부하면서 느낀 것은 오토 인코더의 학습과정은 마치 "압축과 압축해제"와 같다고 느꼈습니다.
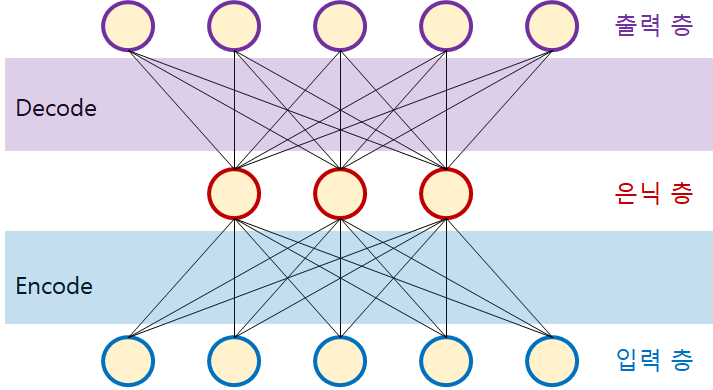
이미지를 학습한다고 가정했을 때, 입력 이미지를 받고, 학습 레이어를 거쳐 입력 이미지를 잘 설명할 수 있는 축소된 차원이 데이터("latent space" 또는 "bottle neck"이라고 하는)로 변환되고, 이 데이터를 다시 reconstruct하여 입력이미지를 복원하거나 target 이미지를 구성해내는 과정을 거친다고 이해했습니다.

조금 더 깊게 생각했을 때, 입력층에서 이미지가 들어오고, 각 노드들은 이에 대한 특징(feature)을 Encoder를 통해 차원 축소를 거치고, 입력 및 target 이미지를 잘 설명할 수 있는 데이터로 압축한 후에 이를 Decoder를 통해 복원하여 표현하는 과정이라고 이해했습니다.
마치 오토 인코더는 PCA와 비슷하다고 생각도 들었습니다. 하지만, PCA는 선형적 차원축소하는 반면 오토인코더는 비선형적 차원축소를 한다고 합니다 (활성함수 이야기 인거 같습니다).
02. Encoder와 Decoder
오토인코더 과정은 3단계로 나누어 볼 수 있을 거 같습니다.
- 데이터 입력
- Encoder
- Decoder
Encoder: Encoder는 결국 입력 데이터를"입력 데이터의 특징을 잘 설명할 수 있는 데이터로 차원 축소한다" 이 공간을 "latent-space", 또는 "bottle neck"이라고 합니다.
Decoder: Decoder는 입력 및 target 데이터로 복원(복호화)을 합니다. decoder가 encoder로부터 받은 데이터로 정확하게 입력 및 target 데이터로 복원한다면 decoder의 성능이 좋다고 표현합니다.
'AI Study' 카테고리의 다른 글
| [AI Study] Object Detection 1-stage vs 2-stage (0) | 2022.01.04 |
|---|---|
| [AI Study] 머신러닝 분류모델 성능 평가 지표 정리 (정밀도, 재현율, 정확도) (0) | 2021.12.31 |
| [AI Study] Confusion Matrix를 통한 모델 성능 평가하기 (0) | 2021.07.06 |
| [머신러닝] 나이브 베이즈 (0) | 2021.06.22 |
| [AI Study] ImageDataGenerator 사용하여 CIFAR-10 분류하기 (0) | 2021.06.22 |
