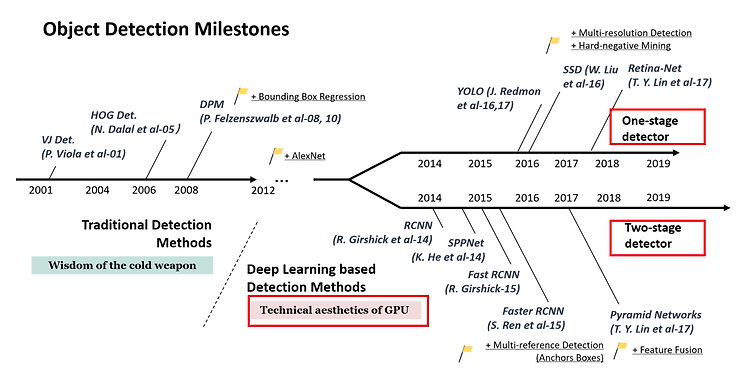
최근 인공지능의 object detection task를 공부하면서 알게 된 서비스입니다.
Roboflow는 컴퓨터 비전(Computer Vision) 기술을 이용해 다양한 애플리케이션을 만들 수 있도록 지원해주는 서비스라고 소개합니다. 웹으로 구성되어 쉽게 사용이 가능하고, 주요한 특징은 무료 데이터셋을 제공하고, 사용자가 가지고 있는 데이터를 업로드하여 annotation을 할 수 있다는 점이 매력적입니다!!
추가적인 데이터를 학습할 대 bounding box를 잡는데 굉장히 용이하였습니다.
아래 그림은 Roboflow가 제공하는 서비스들입니다.
<Roboflow 사용 준비>
Roboflow의 다양한 기능을 사용하기 전에 회원가입을 시작하여야 합니다. 아래의 링크를 통해 회원가입을 진행하세요.
객체 검출 문제는 다수의 사물이 존재하는 이미지나 상황에서 "각 사물의 위치를 파악하고 사물을 분류" 하는 작업입니다.
위 그림을 하나씩 보도록 합시다.
1. Classification: 전통적인 분류 문제는 하나의 이미지를 입력을 받아 해당 이미지가 어떤 클래스인지를 맞추는 문제
2. Classification + Localization: 전통적인 분류를 거치고 나아가 해당 클래스가 존재하는 위치까지 찾는 문제
3. Object Detection: 한 이미지에 다수의 사물이 존재하여 다수의 사물의 위치와 클래스를 찾는 문제
4. Instance Segmentation: 각각의 사물 객체를 픽셀 단위로 다수의 사물의 클래스와 위치를 실제 edge로 찾는 문제
모두 사물을 인식하는 방법에 대한 유형이 되고, Object Detection에서 사용되는 모델 중 하나인 "R-CNN", "Fast R-CNN", "Faster R-CNN"에 대하여 간략히 리뷰하겠습니다.
<R-CNN>
R-CNN은 대표적인 2-stage 방식의 알고리즘 모델이며, Regional Proposal 단계에서 Selective search 방식을 적용하여 2000개의 window를 사용하였습니다.
위 그림을 단계별로 살펴 보겠습니다.
1. 입력 이미지를 받아, "CPU" 상에서 Selective search 방식을 사용하여 약 2000개의 영역을 추출합니다.
2. 추출된 약 2000개의 영역의 이미지를 모두 동일한 input size로 만들기 위해 이미지 crop과 resize을 진행합니다.
3. 2000개의 warped image를 각각 CNN 모델에 입력하여 피처를 추출합니다.
4. 피처 맵을 이용해서 SVM에서는 클래스를, Regressor에서는 클래스의 위치를 bounding box로 찾아냅니다.
특징
1. regional proposal 단계에서 추출한 2000개 영역을 CNN모델에 학습을 해야 합니다.
즉, CNN * 2000 만큼의 시간이 소요되어 수행 시간이 길어집니다.
2. CNN, SVM, Bounding Box Regression 총 세 가지의 모델이 한 번에 학습되지 않지 않습니다.
즉, 학습한 결과가 Bounding Box Regression은 CNN을 거치기 전의 region proposal 데이터가 입력으로 들어가고, SVM은 CNN을 거친 후의 feature map이 입력으로 들어가기 때문에 연산을 공유하지 않고, 그렇기 때문에 end-to-end로 학습할 수 없습니다.
<Fast R-CNN>
Fast R-CNN은 R-CNN이 가지는 단점을 극복한 모델로
1) ROI Max pooling,
2) 영역의 특징 추출을 위한 CNN 모델부터 클래스와 클래스 위치를 찾는 연산까지 하나의 모델에서 학습이 가능하도록 하였습니다. 즉, R-CNN에서 CNN * 2000 만큼의 시간을 CNN * 1 만큼의 시간이 걸리게 되었습니다.
위 그림을 단계별로 살펴보겠습니다.
1. 입력 이미지를 받아, "CPU" 상에서 Selective search 방식을 사용하여 약 2000개의 영역을 추출합니다.
2. 추출된 약 2000개의 영역의 이미지를 모두 동일한 input size로 만들기 위해 이미지 crop만 진행합니다.
3. 입력 이미지를 CNN에 통과시켜 feature map을 추출합니다.
4. 추출된 약 2000개의 영역을 앞서 추출한 feature map에 projection 시킵니다.
5. 추출된 약 2000개의 영역이 projection 된 feature map을 각 ROI에 대한 Pooling을 진행하여 feature vector를 추출합니다.
6. 이 feature vector는 FC layers를 지나서 클래스를 분류하는 "softmax"와 클래스가 있는 bounding box를 찾는 regressor에 각각 입력되고 연산을 거쳐 결과를 도출합니다.
특징
1. R-CNN에서 2000개의 영역에 대한 CNN을 수행하여 시간 소요가 길었지만, ROI pooling을 진행하여 CNN연산을 1번으로 줄었습니다.
즉, CNN * 1 만큼만 시간이 소요되어 수행 시간이 줄었습니다.
2. R-CNN에서 SVM과 regressor가 입력을 공유하지 않기 때문에 "end-to-end" 방식으로 진행하기 어려웠으나, 이를 ROI pooling을 진행함으로써 ROI의 영역을 CNN을 거친 후에 feature map으로 projection 시킬 수 있었습니다.
즉, Bounding Box Regression와, 클래스 분류의 softmax에 CNN을 거친 후의 feature map이 동일한 입력으로 들어가기 때문에 연산을 공유하고, 그렇기 때문에 end-to-end로 학습할 수 있습니다.
3. Fast R-CNN이 R-CNN에 비해 성능과 시간을 효과적으로 향상했으나, 여전히 Region proposal 단계에서 Selective search 알고리즘을 "CPU"상에서 진행되므로 이 부분이 시간이 소요된다는 점이 단점으로 남아있었습니다.
<Faster R-CNN>
Faster R-CNN은 Fast R-CNN이 가지는 단점을 극복한 모델하기 위해 RPN(Region Proposal Network)를 1-stage 단계에서 제안한 방법입니다.
즉, Faster R-CNN의 아이디어는
"Fast R-CNN의 1-stage 단계에서 Region Proposal 방법으로 Selective search이 "CPU" 상에서 진행되니깐, "GPU"를 사용할 수 있도록 Region Proposal 자체도 네트워크를 적용해서 진행해보자!"입니다.
그렇기 때문에 Faster R-CNN은 한마디로 RPN + Fast R-CNN이라 할 수 있으며, Faster R-CNN은 Fast R-CNN구조에서 conv feature map과 RoI Pooling사이에 RoI를 생성하는 Region Proposal Network가 추가된 구조가 되겠습니다.
1. 입력 이미지를 받아, "GPU" 상에서 RPN 네트워크를 사용하여 영역을 추출합니다.
2. RPN 네트워크에서 사물이 있을 법한 영역과 위치를 추출합니다. ("사물이 있다", "사물이 없다" -> 2 softmax)
3. feature map을 각 ROI에 대한 Pooling을 진행하여 feature vector를 추출합니다.
4. 이 feature vector는 FC layers를 지나서 클래스를 분류하는 "softmax"와 클래스가 있는 bounding box를 찾는 regressor에 각각 입력되고 연산을 거쳐 결과를 도출합니다.
차후에 각 R-CNN에 대해 특히나 Faster R-CNN에 대해 상세하게 다루어 보겠습니다.
오토 인코더에 대해서 공부해야 할 일이 생겨서, 하는 도중 정리하기 위해 포스팅을 하게 되었습니다.
공부하여 작성하는 거라, 부족할 수 있으니 많은 피드백 주시면 감사하겠습니다.
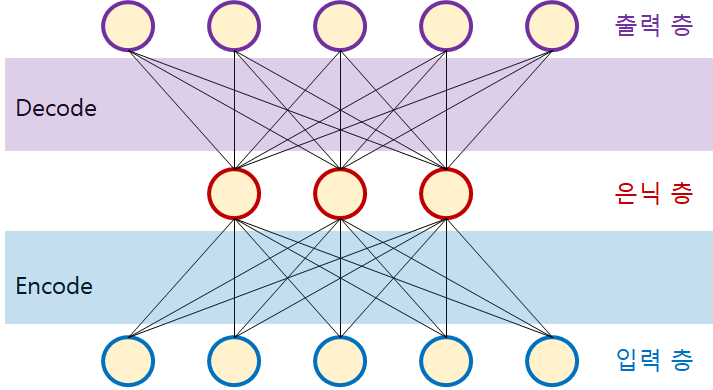
01. 오토 인코더 (autoencoder)
오토 인코더는 비지도 학습 방법의 하나입니다. 그러기 때문에 모델을 학습하기 위한 명확한 라벨(정답)이 제공되지 않습니다. 즉, 오토 인코더를 학습하기 위해서는 입력 데이터를 필요로 합니다.
제가 공부하면서 느낀 것은 오토 인코더의 학습과정은 마치 "압축과 압축해제"와 같다고 느꼈습니다.
이미지를 학습한다고 가정했을 때, 입력 이미지를 받고, 학습 레이어를 거쳐 입력 이미지를 잘 설명할 수 있는 축소된 차원이 데이터("latent space" 또는 "bottle neck"이라고 하는)로 변환되고, 이 데이터를 다시 reconstruct하여 입력이미지를 복원하거나 target 이미지를 구성해내는 과정을 거친다고 이해했습니다.
조금 더 깊게 생각했을 때, 입력층에서 이미지가 들어오고, 각 노드들은 이에 대한 특징(feature)을 Encoder를 통해 차원 축소를 거치고, 입력 및 target 이미지를 잘 설명할 수 있는 데이터로 압축한 후에 이를 Decoder를 통해 복원하여 표현하는 과정이라고 이해했습니다.
마치 오토 인코더는 PCA와 비슷하다고 생각도 들었습니다. 하지만, PCA는 선형적 차원축소하는 반면 오토인코더는 비선형적 차원축소를 한다고 합니다 (활성함수 이야기 인거 같습니다).
02. Encoder와 Decoder
오토인코더 과정은 3단계로 나누어 볼 수 있을 거 같습니다.
데이터 입력
Encoder
Decoder
Encoder: Encoder는 결국 입력 데이터를"입력 데이터의 특징을 잘 설명할 수 있는 데이터로 차원 축소한다"이 공간을 "latent-space", 또는 "bottle neck"이라고 합니다.
Decoder: Decoder는 입력 및 target 데이터로 복원(복호화)을 합니다. decoder가 encoder로부터 받은 데이터로 정확하게 입력 및 target 데이터로 복원한다면 decoder의 성능이 좋다고 표현합니다.
#정답보기
for i in range(32):
pred_label = labels[np.argmax(predictions[i])]
fn = fns[i]
la = labels[label[i]]
print(i, '번째', '파일', fn, '참값', la, '예측값', pred_label)
>>>0 번째 파일 ./CIFAR-10-images-master/test/truck/0959.jpg 참값 truck 예측값 truck
>>>1 번째 파일 ./CIFAR-10-images-master/test/truck/0830.jpg 참값 truck 예측값 truck
>>>2 번째 파일 ./CIFAR-10-images-master/test/bird/0134.jpg 참값 bird 예측값 bird
>>>3 번째 파일 ./CIFAR-10-images-master/test/horse/0935.jpg 참값 horse 예측값 horse
>>>4 번째 파일 ./CIFAR-10-images-master/test/horse/0147.jpg 참값 horse 예측값 horse
>>>5 번째 파일 ./CIFAR-10-images-master/test/dog/0239.jpg 참값 dog 예측값 dog
>>>6 번째 파일 ./CIFAR-10-images-master/test/frog/0285.jpg 참값 frog 예측값 frog
>>>7 번째 파일 ./CIFAR-10-images-master/test/truck/0876.jpg 참값 truck 예측값 truck
>>>8 번째 파일 ./CIFAR-10-images-master/test/deer/0236.jpg 참값 deer 예측값 frog
위의 방법이 있다는 수준으로 전달 드린 것입니다. 결국 참값과 예측값을 비교하는 것이죠!!
이번에는 그림으로 시각화 해보시죠!
예측한 데이터와 정답 이미지로 확인 하기
#이미지 데이터를 랜덤하게 n개 추출하여 라벨, 파일이름, 이미지 배열 추출 함수
def load_rand_img(imagesset, randint):
images = imagesset.filepaths
labels = imagesset.labels
rand_imgs = []
label = []
for i in range(randint):
rand_num = random.randrange(0,len(images))
rand_imgs.append(images[rand_num])
label.append(labels[rand_num])
load_imgs = load_img(rand_imgs)
return label, rand_imgs, load_imgs
# 예측 결과를 figure로 확인하는 함수
def plot_predict(figsize, num, classes, label, images, predictions):
fig = plt.figure(figsize=(figsize[0], figsize[1]))
for i in range(num):
plt.subplot(figsize[0], figsize[1], i + 1)
plt.grid(False)
plt.xticks([])
plt.yticks([])
fn = plt.imread(images[i])
plt.imshow(fn)
la = classes[label[i]]
pred_label = classes[np.argmax(predictions[i])]
if pred_label == la:
color = 'green'
else:
color = 'red'
plt.xlabel("{}({}, i={})".format(pred_label, la, i), color=color)
plt.show()
# 메인 실행
labels = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
label, fns, images2 = load_rand_img(images, 10000)
predictions = model.predict(images2/255)
plot_predict((4,8),32, labels, label, fns, predictions)
xlabel의 형식은 "예측값(참값)" 으로 설정하였습니다.
이번 시행에서 32개 중에 7개 오답을 보였으니, 약 22%의 오답률, 즉 78% 정답률을 보여주었지만, 해당 코드는 실행할 때마다 다시 랜덤추출하기 때문에 한눈에 모델을 평가하기는 어렵습니다!!
그래서!! 모델의 성능을 한눈에 보기위해 "Confusion Matrix"를 적용해보았습니다!!
예측한 데이터와 정답을 "Confusion Matrix"로 확인 하기
Confusion Matrix에 대해 잠깐 본다면 참값(타겟의 원래 클래스)와 예측값(모형이 예측한 클래스)가 일치하는지를 갯수로 수치화 한 결과 표라고 보시면 되겠네요!
정답 클래스는 행(row)로, 예측 클래스는 열(column)로 표현하기때문에, Confusion Matrix는 모델이 잘 작동되는지 확인할 수 있는 좋은 방법입니다.
keras에서는 이미지데이터 학습을 쉽게하도록 하기위해 다양한 패키지를 제공한다. 그 중 하나가 ImageDataGenerator 클래스이다.
ImageDataGenerator 클래스를 통해 객체를 생성할 때 파라미터를 전달해주는 것을 통해 데이터의 전처리를 쉽게할 수 있고, 또 이 객체의 flow_from_directory 메소드를 활용하면 폴더 형태로된 데이터 구조를 바로 가져와서 사용할 수 있다.
이 과정은 매우 직관적이고 ImageDataGenerator를 사용하지 않는 방법에 비해 상당히 짧아진다.
ImageDataGenerator를 통해 parameter arugmentation을 하고, flow_from_directory
메소드를 사용해, 폴더를 특정 사이즈로 이미지를 불러올 수 있다.
02. CIFAR-10 학습해 보기
학습과정은 기본적인 FLOW를 배경으로 하였다.
이미지로드
train 과 validation 데이터 분리
이미지 전처리 (정규화 포함, DATAGENERATOR, 원핫인코딩)
학습모델형성
학습진행
학습평가 (시각화)
01. 이미지 로드
지난 시간에 subplot의 대한 사용법을 복습하고, rows: labels, columns 각 이미지로 하여,
10 x 10의 이미지를 추출해보았다. 데이터 탐색의 목적으로, 데이터 확인이 목적이다.
ex) 비행기는 비행기네,, 트럭은 트럭이네,, 등등 < 실무에 이러한 작업이 필수적>
CIFAR-10 이미지 플롯
02. train과 validation 데이터 분리
이 과정은 추가적으로 진행하게 된 작업이다. 기본적으로 데이터가 주어지면 train set, validation set, test set으로 구분해야 한다.
목적은 "Overfitting"!! 즉, 내가 만든 모델이 내가 제공한 train set데이터에 너무 과적합되도록 학습되어버려서 이를 조금이라도 벗어난 케이스에 대해서 예측률이 낮아지는 현상이 발생한다. 그렇기 때문에 이러한 현상을 막기 위해서 데이터를 목적에 맞도록 구분한다.
train set : 모델이 훈련하는 데이터셋
validation set : train set 학습 중간에 모델 평가에 사용되는 데이터셋 (모델 성능에 영향 줌)
test set : 오로지 모델의 성능 평가를 위해 사용되는 데이터셋 (모델 성능에 영향 안 줌)
이번 주차에서는 train set을 train을 위한 데이터셋과 validation을 위한 데이터셋으로 나누어 볼 것이다. 아주 간단하다. 왜냐하면, ImageDataGenerator과 flow_from_directory에서 쉽게 할 수 있다.
[train set, validation set] = [0.8, 0.2]로 나누어 볼 것이다.
핵심은,ImageDataGenerator로 argumentation에서 "validation_split"을 지정한 후에 (내가 원하는, 이는 이미지 전처리와 같음) 각flow_from_directory시에 "subset"을 지정해주면 된다. 5만 장으로 구성되었던, train directory의 데이터를 학습에 4만 장, 1만 장으로 나누었다. Good!
데이터 분할
03. 이미지 전처리
이미지 전처리에서는ImageDataGenerator로 argumentation를 통해데이터 학습을 위한1) 데이터 가공 (정규화)과2) 데이터 뻥튀기를 통해 많은 데이터를 모델이 학습할 수 있도록 하는 역할이 있다. 생각할수록 굉장히 유용한 클래스이다.. overfitting 방지
이를 통해 두 가지를 한 번에 하는 마법 같은 경험을 하였다
#개수작을 좋아하는 나는 사용할 수 있는 모든 argumentation을 최대한 활용하였다.
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=15,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
validation_split=0.2)
rescale:정규화 위해
rotation_range = 0~15도 까지 회전하기
shear_range = 시계반대방향으로 밀림,0.2이라면, 0.2 라이안내외로
시계반대방향으로 변형
zoom_range = “1-수치”부터 “1+수치”사이 범위로 확대/축소,0.2이라면,
0.8배에서 1.2배 크기 변화를 시킴
horizontal_flip = 수평방향으로 뒤집기
width_shift_range, height_shift_range = 0.1 배율의 픽셀 만큼 이동
진짜 돌아가는 건지, 그러니깐 ImageDataGenerator가 구동되는지 궁금했다.
CIFAR10의 비행기 그림
airplane의 하나를 해당 조건으로 25장의 이미지로 만들어 저장하여 불러보았다.
뭐,,, 확실히 이미지의 변화가 생긴 거 같긴 하다. ok!
ImageDataGenerator를 통해 argumentation 수행 결과
import numpy as np
import os
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator,
array_to_img, img_to_array, load_img
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=15,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
validation_split=0.2)
img = load_img('./CIFAR-10-images-master/train/airplane/0001.jpg')
plt.figure()
a = plt.imread(img)
plt.imshow(a)
plt.show()
x = img_to_array(img)
x = x.reshape((1,) + x.shape)
i = 0
for batch in train_datagen.flow(x, batch_size=20,
save_to_dir='./CIFAR-10-images-master/tmp_files', save_prefix='tmp',
save_format='jpg'):
i += 1
if i > 24:
break
image_dir = './CIFAR-10-images-master/tmp_files'
plt.figure(figsize=(5,5))
images = os.listdir('./CIFAR-10-images-master/tmp_files')
for i in range(5):
for j in range(5):
plt.subplot(5,5,i*5 +j + 1)
fn = image_dir+ '/' + images[i]
image = plt.imread(fn)
plt.grid(False)
plt.tight_layout()
plt.imshow(image)
plt.show()
04. 이미지 모델 생성 & 학습 진행 & 학습평가 (시각화)
여러 가지 모델에 대하여 생성하고, 학습하고 평가까지 한 번에 해보았다. 코드 스플릿이 필요하긴 할 듯,, 다음에..
기본적은 CNN이며 둘 차이는 layer 수와 optimizer를 두었다.
이전과 다른 것은 ImageDataGenerator로 데이터를 전처리 및 부풀렸기 때문에, model에 대하여 fit() 메서드를 사용하는 것이아니라, fit_generator() 메소드를 사용한다는 것! 중요!
Accuracy가 높아지지 않았지만, validation의 accuracy가 train의 accuracy보다 높다...(?)
왜지?? 이는, train set에서 과적합이 발생하지 않고, validation set에서 잘 맞추었다는 이야기로, 정확도는 낮지만 bias와 variance가 낮은 모델이라고 볼 수 있다.
여기서 과적합에 대한 내용을 잠시 담자면, 조금 찾아보니깐, →"validation set의 accuracy가 train set보다 낮다면, Regularization을 계산 반복해야 한다."
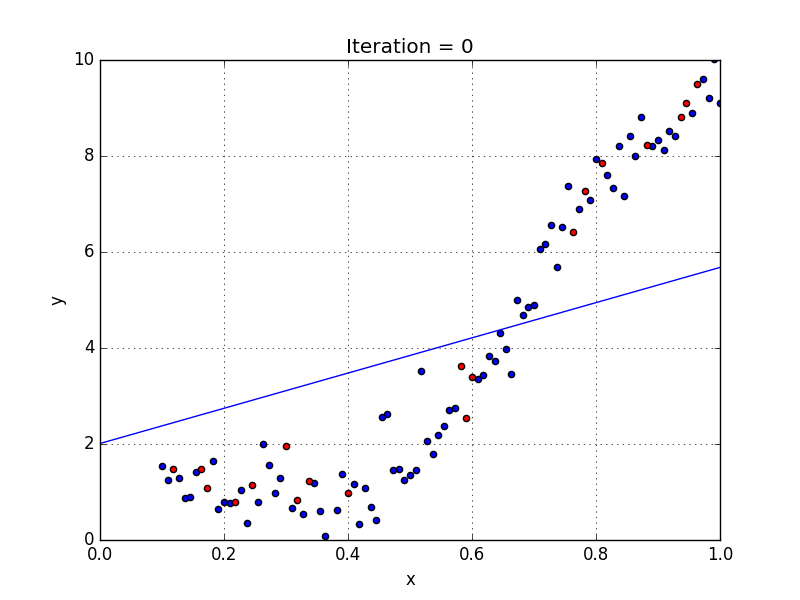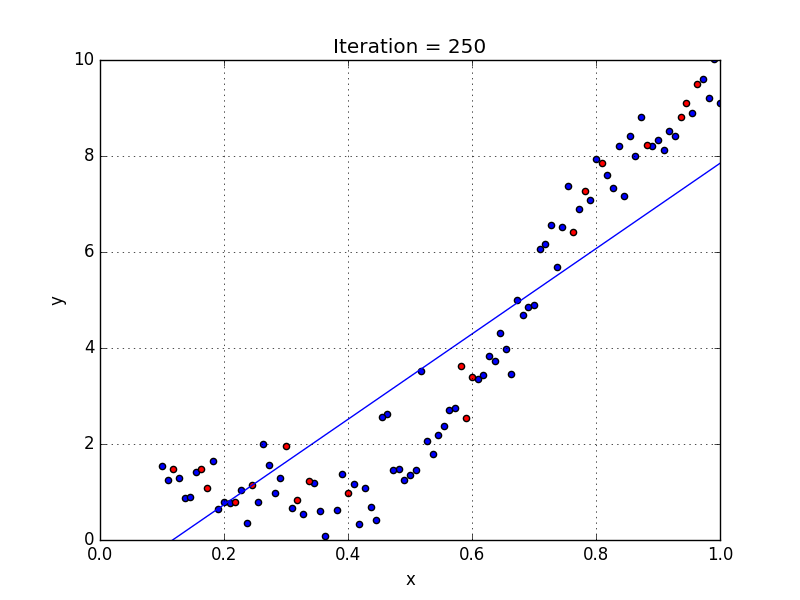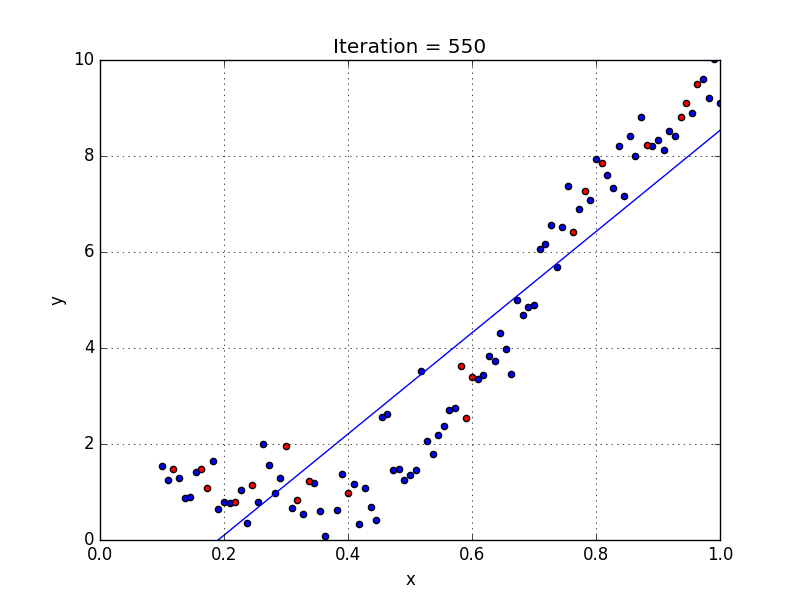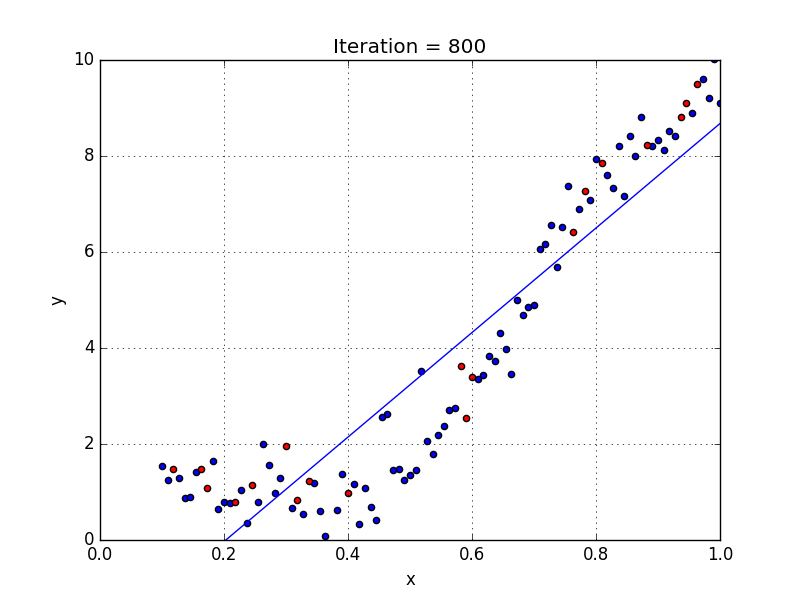
이 말을 이해하고자 다음 그림을 인용해보았다.
정규화에 대한 자료 (인용)
작성자는 이렇게 말한다."overfitting 그래프(3번째)를 보면, 데이터 분포에 비해서 loss함수가 복잡해지고, smooth 하지 않다. 즉, 새로운 데이터를 넣으면 제대로 예측하지 못할 가능성이 높다."
2번째의 그래프의 경우 데이터 분포와 조화가 잘되어 smooth 하다, 이러한 곡선이 적절한 모델일 가능성이 높다고 한다. 이는 변동성을 낮추어야 한다고 하는데,, 잘 이해는 되지 않는다 다만 앞서 말한 것처럼 변동성을 낮추기 위해서 "Regularization" 이 필요하다고 한다.
그럼 해보자!
옵티 아미저는 model1과 함께 가고, epoch 늘리고 layers는 model2를 따라가는데,
Regularization을 layer마다 추가해보자! 어떻게? 케라스에서 친절히 제공한다.
의사결정 트리 알고리즘은 데이터를 어떤 특징 속에서 연속적으로 분리하여 관측값과 목표값을 연결시켜주는 예측 모델로 사용됩니다.
의사결정 트리의 큰 장점은 이러한 예측모델의 과정을 시각적이고 명시적으로 표현이 가능합니다.
의사결정트리 - 출처: 위키백과
위의 그림과 같이 데이터의 특징 속에서 분류에 큰 영향을 끼치는 특징을 발견하고, 상위노드로 선택하는 알고리즘이 핵심입니다.
💡 여기서 상위노드는 어떤의미일까?
결정 트리에서 질문이나 정답을 담은 모든 박스들을 "노드(Node)"라고 일컫습니다.
또한, 분류 기준(첫 질문)을 Root Node라고 하고, 맨 마지막 노드를 Terminal Node(혹은 Leaf Node) 라고 합니다. 의사 결정트리는 각 노도의 정의한 특징에 따라 아래로 가면서 하단의 노드를 선택하는 알고리즘으로 보이는데 "왜 상위노드" 를 선택한다고 하는지는 의사결정 트리라는 이름이 붙은 이유에서 찾을 수 있습니다.
"Decision Tree"라고 불리는 의사결정 트리는 위의 그림을 전체적인 모양이 나무를 뒤짚어 놓은 것과 같아보이는 것에서 이름이 붙여졌기 때문에 사실상, 상위노드는 Root Node → Terminal Node (Leaf Node)로 가는 방향을 표현 한 것이겠네요!
2.1. 의사결정 트리 알고리즘과 정보 엔트로피의 관계
앞서 말씀드린 것처럼, 의사결정 트리 알고리즘은 각 루트 노드(분류기준)에 따라 스무고개 하듯이 각 노드의 특징을 통해 상위노드를 선택해 나가는 알고리즘입니다. 이런 과정에서 약간씩의 정보를 획득합니다.
정보를 획득한다는 말은 "정답에 대한 불확실성이 줄어든다는 개념" 입니다.
해당 개념을 "정보 이론"에서 불리는 "엔트로피"의 개념을 차용하여 부릅니다.
정보의 획들을 정보 이득이라고 합니다. 아래의 식이 성립합니다.
정보이득에 대한 엔트로피 관점의 수식
💡 질문 후 정보 이득 = 질문 전의 엔트로피 - 질문 후의 엔트로피 즉, 의사결정 트리 알고리즘은 엔트로피가 낮아지는 방향으로 노드가 나아가는 것이겠네요!
즉, 정보의 획등이 최대화하는 방향으로 학습이 진행된다는 것이구요!
💡 정보의 획득이 정답에 대한 불확실성을 줄인다는 것을 이해했는데, 이게 정보이론의 "엔트로피"와 무슨 상관일까??
간단하게 말해서, 정보이론의 엔트로피는 "무질서함"을 이야기하고 이는 "불확실성"에 대한 개념을 내포하고 있습니다. 이를테면, 마음먹고 정리한 내 책상은 이틀 뒤에 지저분해져있습니다.