from PIL import Image, ImageDraw
# 설정하고자 하는 밝기도
luminosity = 80
# 이미지 로드
input_image = Image.open("input.png")
input_pixels = input_image.load()
# 출력 이미지 생성
output_image = Image.new("RGB", input_image.size)
draw = ImageDraw.Draw(output_image)
# 이미지의 픽셀에 밝기도 더하여 출력
for x in range(output_image.width):
for y in range(output_image.height):
r, g, b = input_pixels[x, y]
r = int(r + luminosity)
g = int(g + luminosity)
b = int(b + luminosity)
draw.point((x, y), (r, g, b))
output_image.save("output.png")
<Contrast 대조도>
Contrast는 이미지의 밝은 부분과 어두운 부분의 차이를 의미하고, 이를 조절한다는 것은 이미지의 밝은 부분과 어두운부분의 차이를 조절한다는 의미입니다. 이는 이미지내의 물체를 선명하게 보는 효과를 가지고 옵니다.
예를들어, 이미지 안의 픽셀들이 대부분은 비슷한 Intensity(값)을 가진다면 어떨까요?
이미지는 아래와 같이 어떠한 물체 정보도 얻기 힘들 것입니다.
이 경우를 대조도가 낮다 라고 말할 수 있습니다. 반면에, 대조도가 높다는 것은 이미지 내의 물체를 식별하는데 용이하고 이는 선명하다 라는 느낌을 주게됩니다.
<Contrast 대조도 - 구현>
앞서 말씀드린 것처럼 대조도가 높다는 것은 이미지 내의 물체를 식별하는데 용이하고, 선명하다 라는 느낌을 주게됩니다. 즉, 대개는 대조도를 높여 이미지를 선명하게 하는 것이 이미지의 질을 높이는 방향일 것입니다.
어떻게 대조도를 만드느냐에 대해는 여러가지 방법론이 있습니다. 하지만 핵심은 "intensity 값의 곱" 입니다.
즉, 입력이미지의 픽셀에 어떠한 조정 값을 곱하여 대조도를 변경 할 수 있습니다.
예를 들어, A라는 픽셀은 100이라는 Intensity를 가지고, B라는 픽셀은 50이라는 intenstiy를 가진다고 가정합니다.
Contrast를 높이기 위해 두 픽셀 값에 대해 1.5를 곱한다고 하면, A= 150, B=75가 됩니다.
1.5를 곱하기 전의 A-B의 값은 50이였지만, 1.5를 곱한 후의 A-B의 값은 75입니다.
즉, 두 픽셀의 값의 차이가 더 벌어진 것입니다. 이러한 원리로 대조도를 조정합니다.
이때 곱해지는 값을 정하는 방법은 여러가지가 있습니다.
from PIL import Image, ImageDraw
# Load image:
input_image = Image.open("input.png")
input_pixels = input_image.load()
# Create output image
output_image = Image.new("RGB", input_image.size)
draw = ImageDraw.Draw(output_image)
# Find minimum and maximum luminosity
imin = 255
imax = 0
for x in range(input_image.width):
for y in range(input_image.height):
r, g, b = input_pixels[x, y]
i = (r + g + b) / 3
imin = min(imin, i)
imax = max(imax, i)
# Generate image
for x in range(output_image.width):
for y in range(output_image.height):
r, g, b = input_pixels[x, y]
# Current luminosity
i = (r + g + b) / 3
# New luminosity
ip = 255 * (i - imin) / (imax - imin)
r = int(r * ip / i)
g = int(g * ip / i)
b = int(b * ip / i)
draw.point((x, y), (r, g, b))
output_image.save("output.png")
오토 인코더에 대해서 공부해야 할 일이 생겨서, 하는 도중 정리하기 위해 포스팅을 하게 되었습니다.
공부하여 작성하는 거라, 부족할 수 있으니 많은 피드백 주시면 감사하겠습니다.
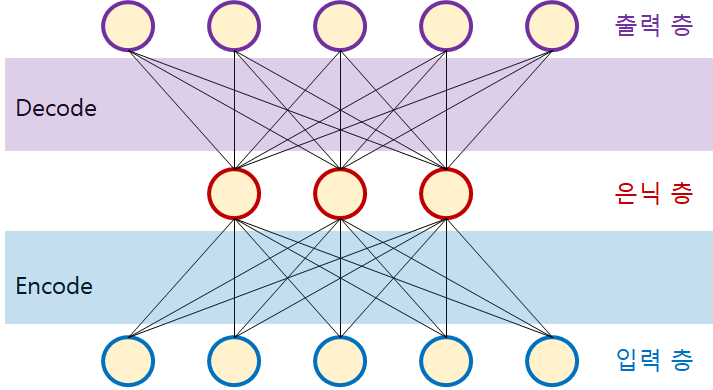
01. 오토 인코더 (autoencoder)
오토 인코더는 비지도 학습 방법의 하나입니다. 그러기 때문에 모델을 학습하기 위한 명확한 라벨(정답)이 제공되지 않습니다. 즉, 오토 인코더를 학습하기 위해서는 입력 데이터를 필요로 합니다.
제가 공부하면서 느낀 것은 오토 인코더의 학습과정은 마치 "압축과 압축해제"와 같다고 느꼈습니다.
이미지를 학습한다고 가정했을 때, 입력 이미지를 받고, 학습 레이어를 거쳐 입력 이미지를 잘 설명할 수 있는 축소된 차원이 데이터("latent space" 또는 "bottle neck"이라고 하는)로 변환되고, 이 데이터를 다시 reconstruct하여 입력이미지를 복원하거나 target 이미지를 구성해내는 과정을 거친다고 이해했습니다.
조금 더 깊게 생각했을 때, 입력층에서 이미지가 들어오고, 각 노드들은 이에 대한 특징(feature)을 Encoder를 통해 차원 축소를 거치고, 입력 및 target 이미지를 잘 설명할 수 있는 데이터로 압축한 후에 이를 Decoder를 통해 복원하여 표현하는 과정이라고 이해했습니다.
마치 오토 인코더는 PCA와 비슷하다고 생각도 들었습니다. 하지만, PCA는 선형적 차원축소하는 반면 오토인코더는 비선형적 차원축소를 한다고 합니다 (활성함수 이야기 인거 같습니다).
02. Encoder와 Decoder
오토인코더 과정은 3단계로 나누어 볼 수 있을 거 같습니다.
데이터 입력
Encoder
Decoder
Encoder: Encoder는 결국 입력 데이터를"입력 데이터의 특징을 잘 설명할 수 있는 데이터로 차원 축소한다"이 공간을 "latent-space", 또는 "bottle neck"이라고 합니다.
Decoder: Decoder는 입력 및 target 데이터로 복원(복호화)을 합니다. decoder가 encoder로부터 받은 데이터로 정확하게 입력 및 target 데이터로 복원한다면 decoder의 성능이 좋다고 표현합니다.
객체란, 어떠한 속성의 값, 행동을 가지는 데이터를 일컫습니다. 파이썬에서 숫자, 문자, 함수 등등 모든 데이터들은 여러 속성과 행동을 가지고 있고 각각이 객체라 볼 수 있습니다.
예시)
세탁기라는 객체는 "빨래를 한다", "빨래 정지한다", "가로 100cm" 등의 속성과 행동으로 표현할 수 있습니다. 이렇든 정의된 데이터가 속성과 행동을 가진다면 객체라고 말할 수 있겠네요!
클래스는 위와 같은 특성을 가지는데요, 왜 그러한지에 대해 차근차근 보겠습니다.
02. 클래스는 복잡한 문제를 다루기 쉽게 한다?
아래의 예시를 통해 이를 확인 할 수 있습니다.
클래스를 통해 복잡하게 반복해야하는 행동을 쉽게 정의하여 해결 할 수 있습니다.
곱셈 계산 기능을 가지는 계산 프로그램 multiply가 있습니다.
이 계산 프로그램은 현재 까지 입력된 모든 숫자들의 곱을 구해야합니다.
예시)
result = 1
def multiply(num):
global result
result *= num
return result
print(multiply(3))
print(multiply(4))
print(multiply(6))
[out]
3
12
72
그런데, 어떠한 상황에서 multiply의 기능을 하는 계산 프로그램이 두개가 필요하다고 생각해봅시다.
예를들어, 1 x 4 x 10 라는 연산과 20 x 4 라는 연산을 한번에 진행해야 할 때, 이러한 상황을 고려해보면 위 와같은 multiply 프로그램을 multiply_1, multiply_2와 같이 두개를 만들어야 합니다.
예시)
result_1 = 1
result_2 = 1
def multiply_1(num):
global result_1
result_1 *= num
return result_1
def multiply_2(num):
global result_2
result_2 *= num
return result_2
print(multiply_1(1))
print(multiply_1(4))
print(multiply_1(10))
print(multiply_2(20))
print(multiply_2(4))
[out]
1
4
40
20
80
좋습니다. 2개까지는 충분히 만들 수 있을거 같습니다. 하지만, 5개, 20개 혹은 그이상이 필요할 때는 어떻게 해야할까요, 하나하나 직접 구현 하는 것은 굉장히 복잡하고, 비효율적입니다.
여기서! 클래스는 이러한 상황을 매우 간단하게 해결합니다!
예시)
#Multiply 클래스 생성
class Multiply:
def __init__(self):
self.result = 1
def multiply(self, num):
self.result *= num
return self.result
# 클래스를 통한 계산기 1
multiply_1 = Multiply()
print("계산기 1 결과")
print(multiply_1.multiply(2))
print(multiply_1.multiply(5))
# 클래스를 통한 계산기 2
multiply_2 = Multiply()
print("계산기 2 결과")
print(multiply_2.multiply(10))
print(multiply_2.multiply(9))
위와 같이 Multiply라는 클래스를 생성하여, multiply_1, multiply_2의 인스턴스를 형성하여 사용할 수 있습니다!
많이 비유되는 거처럼, 클래스는 마치 틀, 공장과 같은 역할을 해서 자신의 형태 결과물인 인스턴스를 만들어냅니다!
3. 객체의 클래스는 초기화를 통해 제어?
클래스를 생성하고 생성된 클래스를 인스턴스로 형성하여 반복적으로 기능을 할 수 있는 것이 클래스의 특징인데요, 여기서 항상 들어가는 "__init__()" 이라는 함수가 있습니다.
이는 생성자라하며, 인스턴스가 생성될때 항상 실행되는 것입니다.
즉, 위의 Multiply라는 클래스를 통해, Multiply_1, Multiply_2 라는 두개의 인스턴스가 생성되었는데요, 생성할때마다 __init__() 함수가 실행되면서 모두 self.result = 1이라는 문장을 실행합니다.
즉, result라는 변수를 인스턴스 형성때마다 초기화가 됩니다. 이러한 장점은 많은 변수를 추가할 필요없게 합니다.
💡메모
클래스에는 생성자와 소멸자라는 개념이 있습니다.
생성자는 위에서 설명한 "__init__()"에 해당되며, 이 생성자를 통해서 객체가 생성될때 어떤 변수의 값을 세팅하는 등 여러가지 작업을 할 수 있습니다.
반면에, "__del__()" 라는 소멸자는 리소스 해제등의 종료 작업을 하기위해 사용됩니다.
#Multiply 클래스 생성
class Multiply:
def __init__(self):
self.result = 1
def multiply(self, num):
self.result *= num
return self.result
#클래스가 인스턴스로 형성될 때마다 __init__() 함수는 실행된다.
#즉 result 인스턴스 형성 마다 개별적으로 초기화
4. 클래스는 객체의 구조와 행동을 정의?
이 특징은 위를 잘 읽으셨다면 충분히 이해 하실 겁니다.
즉, 어떠한 객체에 대해 복잡한 구조를 만들 필요 없이 클래스를 통해서 객체에 대한 행동과 속성을 구조화 시켜 간단하게 해결 할 수 있습니다!!
가장 기본적인 예제인 MNIST 데이터셋을 이용하여 손글씨 데이터를 분류 예측하는 모델 제작.
케라스에서 MNIST 데이터셋을 numpy배열 형태로 호출이 가능하다.
# 필요한 라이브러리 불러오기
from keras.datasets import mnist
from keras import models
from keras import layers
from keras.utils import to_categorical
# MNIST 데이터셋 불러오기
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 이미지 데이터 준비하기 (모델에 맞는 크기로 바꾸고 0과 1사이로 스케일링)
# 노말라이즈를 하는, 0~1의 이미지를 기준으로 한다. (왜그런지 보쟈)
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
02. 훈련, 테스트 데이터 설정
# 레이블을 범주형으로 인코딩
train_labels = to_categorical(train_labels) #범주형이라고하고, 원핫인코딩 필수적인 작업
#원핫 인코딩 왜하냐 알아보기.
test_labels = to_categorical(test_labels)
03. 모델 정의
# 모델 정의하기 (여기에서는 Sequential 클래스 사용)
model = models.Sequential()
model.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,))) 512개의 perceptron
model.add(layers.Dense(10, activation='softmax'))
model.add(layers.Dense(len(train_labels[0]), activation='softmax'))
# 모델 컴파일 하기
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
04. 모델 훈련
# fit() 메서드로 모델 훈련 시키기
model.fit(train_images, train_labels, epochs=5, batch_size=128)
National Institute of Standards and Technology의 줄임말로, 미국 국립표준기술연구소의 손으로 쓴 글자 데이터셋에서 숫자만 따로 뽑아낸 데이터 셋.
0~255사이의 값을 가지는 흑백 이미지이며 28x28(784) 사이즈를 지니며 7만 개의 이미지(6만 개 트레이닝 셋, 1만 개 테스트 셋)으로 구성되어있다.
02. MNIST 데이터 셋 살펴보기
# 필요한 라이브러리 불러오기
from keras.datasets import mnist
from keras import models
from keras import layers
from keras.utils import to_categorical
# MNIST 데이터셋 불러오기
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
------------------------------------------------------------------------------
test_image : shape : (10000,28,28) 28x28 이미지 10000장
test_label : shape : 10000 10000장 이미지 대한 0~9까지의 라벨
train_image : shape : (60000,28,28) 28x28 이미지 60000장
train_label : shape : 60000 60000장 이미지 대한 0~9까지의 라벨
* 각 한장에 28x28 배열이며 각 배열의 값들은 0~255의 값을 가지고 이미지로 보았을때
0~9까지의 형상을 가진다
03. MNIST 데이터 셋 PLOT 해보기
import matplotlib.pyplot as plt
#train image의 5번째 이미지 추출
image = train_images[4] #reshape전의 이미지
#plot the sample
fig = plt.figure
plt.imshow(image, cmap='gray')
plt.show()
print("train_image 4번째 라벨은", train_labels[4])
#실행결과 Console: train_image 4번째 라벨은 9
04. 모델구조 파악하기
모델을 정의하는 방법은 두 가지로, Sequential 클래스와 함수형 API를 사용한다.
1) Sequential 클래스 : 가장 자주 사용하는 구조로, 층을 순서대로 쌓아 올린 네트워크
2) 함수형 API : 완전히 임의의 구조를 만들 수 있는 비순환 유향 그래프(DAG) 만듬 ( 공부가 필요)
해당 코드에서는, Sequential 클래스 형태로 모델화하였다.
모델은 2개의 Dense 층으로 되어있고, 각각 "relu", "softmax"의 활성함수를 가진다.
마지막 층은 10개의 확률 점수가 들어 있는 배열을 반환하는 소프트맥스층이며, 각 점수는 현재 숫자 이미지가 10개의 숫자 클래스 중 하나에 속할 확률을 나타낸다(?)
#model.summary() 통해 전체적인 구조
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 512) 401920
_________________________________________________________________
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 407,050
Trainable params: 407,050
Non-trainable params: 0
_________________________________________________________________
05. 결과 파악하기
학습된 모델이 Test 모델을 판별할때, 98.34%로 MNIST의 숫자를 맞춘다는 의미이다.
즉, 테스트 데이터 10000개 중에서 200장 가량 틀렸다는 것으로 볼 수 있다.
Test loss: 0.08414454758167267
Test accuracy: 0.9817000031471252
예측 라벨과 실제 테스트라벨이 다른 결과들 16개를 랜덤하게 선정하여 보았을때, 실제로 사람이 보아도 판별하기 쉽이낳는 것들이 있는 것을 확인 할 수 있다.
04. 전체코드
01. 학습하기
# 필요한 라이브러리 불러오기
from keras.datasets import mnist
from keras import models
from keras import layers
from keras.utils import to_categorical
import matplotlib.pyplot as plt
from keras.utils import plot_model
# MNIST 데이터셋 불러오기
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# 이미지 데이터 준비하기 (모델에 맞는 크기로 바꾸고 0과 1사이로 스케일링)
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255
# 레이블을 범주형으로 인코딩
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
# 모델 정의하기 (여기에서는 Sequential 클래스 사용)
model = models.Sequential()
model.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
model.add(layers.Dense(10, activation='softmax'))
model.summary()
# 구 조확인
from IPython.display import SVG
from keras.utils import model_to_dot
# SVG(model_to_dot(model, show_shapes=True).create(prog='dot',format='svg'))
# 모델 컴파일 하기
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# fit() 메서드로 모델 훈련 시키기
history=model.fit(train_images, train_labels,epochs=10, batch_size=64, verbose=1)
# batch size가 높을수록, 속도빠르고, 정화도가 낮아.
# 테스트 데이터로 정확도 측정하기
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=0)
print('Test loss:', test_loss)
print('Test accuracy:', test_acc)
# 학습 정확성 값과 검증 정확성 값을 플롯팅 합니다.
#결과파악.
import random
import numpy as np
predicted_result = model.predict(test_images)
predicted_labels = np.argmax(predicted_result, axis=1)
test_label = np.argmax(test_labels, axis=1)
wrong_result = []
for n in range(0, len(test_label)):
if predicted_labels[n] != test_label[n]:
wrong_result.append(n)
samples = random.choices(population=wrong_result, k=16)
count = 0
nrows = ncols = 4
plt.figure(figsize=(12,8))
for n in samples:
count += 1
plt.subplot(nrows, ncols, count)
plt.imshow(test_images[n].reshape(28, 28), cmap='Greys', interpolation='nearest')
tmp = "Label:" + str(test_label[n]) + ", Prediction:" + str(predicted_labels[n])
plt.title(tmp)
plt.tight_layout()
plt.show()
02. 결과보기
from keras.datasets import mnist
# MNIST 데이터셋 불러오기
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
import matplotlib.pyplot as plt
#train image의 4번째 이미지 추출
image = train_images[4]
#plot the sample
fig = plt.figure
plt.imshow(image, cmap='gray')
plt.show()
print("train_image 4번째 라벨은", train_labels[4])
num = 10
images = train_images[:num]
labels = train_labels[:num]
num_row = 2
num_col = 5
#plot images
fig, axes = plt.subplots(num_row, num_col, figsize=(1.5*num_col, 2*num_row))
for i in range(num):
ax = axes[i//num_col, i%num_col]
print(i//num_col, i%num_col)
ax.imshow(images[i], cmap='gray')
ax.set_title('Label: {}'.format(labels[i]))
plt.tight_layout()
plt.show()