위 함수는 name, university라는 변수를 받아 출력합니다. 하지만, 사용자가 새로운 파라미터를 추가하고 싶다면, 이 함수를 바꾸어야 할 것입니다. 굉장히 번거로운 일이 될 것입니다.
그래서 "딕셔너리 형"을 이용해서 아래와 같은 함수를 만들 수 있을 것입니다.
def print_keyword_dict(dictionary):
for key in dictionary:
print(key + ": " + dictionary[key])
위 함수는 dictionary를 받아서, key를 통해 해당 값을 출력할 수 있기 때문에 dictionary에 새로운 파라미터를 추가하여 출력할 수 있습니다. 하지만, "딕셔너리 형"을 구성해야 한다는 불편한 점이 있습니다.
이런 경우 **kwargs를 사용하여 해결할 수 있습니다.
def print_keyword_kwargs(**kwargs):
for key in kwargs:
print(key + ": " + kwargs[key])
**kwargs는 함수 내에서 kwargs로 딕셔너리 형을 받아내기 때문에 키워드 인자를 저장합니다.
# **kwargs 적용 전 함수
print_keyword_dict({"name":"jaehwan", "university":"seoul", "studentID":"123155"})
# **kwargs 적용 후 함수
print_keyword_kwargs(name="jaehwan", university="seoul", studentID="123155")
훨씬 깔끔하고, 사용하기 편한 함수가 된 거 같습니다.
요약
함수에 위치 인자를 받고 싶을 때! -> *args 사용! 리스트형으로 받아내기 때문에 위치(순서)대로 받아 처리!
함수에 키워드 인자를 받고 싶을 때! -> **kwargs 사용! 딕셔너리형으로 받아내기 때문에 키워드에 따라 값을 받아 처리!
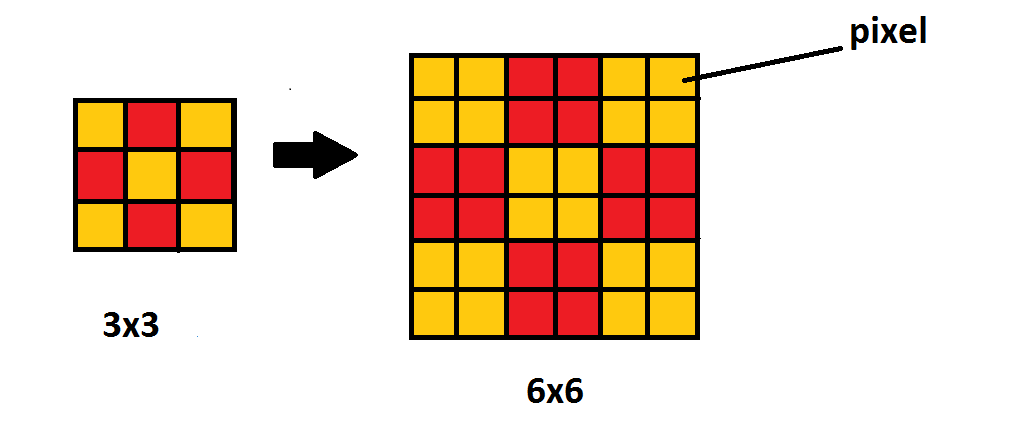
import cv2
import numpy as np
from math import floor
#Load image
img = cv2.imread('./../Image01.png')
print(img.shape, img.dtype)
height = img.shape[0]
width = img.shape[1]
#Scale
target_size = (300, 300) # target size
output = np.zeros((target_size[0], target_size[1], 3), np.uint8)
x_scale = height/output.shape[0] #input image / output image
y_scale = width/output.shape[1] #input image / output image
for y in range(output.shape[1]):
for x in range(output.shape[0]):
# the pixel at coordinate (x, y) in the new image is equal to the pixel that is located at coordinate (floor(x * x_ratio), floor(y * y_ratio)).
# floor는 인접한 픽셀을 가져오기 위해서 사용
xp, yp = floor(x* x_scale), floor(y * y_scale)
print(xp, yp)
print(x, y)
output[x,y] = img[xp,yp]
cv2.imwrite('./scale.png', output)
<opencv>
# cv2.reize()로 이미지 확대 및 축소 (scale_resize.py)
import cv2
import numpy as np
img = cv2.imread('../Image01.png')
height, width = img.shape[:2]
target_size = (300,300)
scale_img = cv2.resize(img, (target_size[0], target_size[1]), \
interpolation=cv2.INTER_AREA)
cv2.imwrite('./scale_cv.png', scale_img)
resize 함수를 통하여 간단하게 구현이 가능하며, 보간법은 영상 축소 시 효과적인 INTER_AREA(Nearest Neigbour 계열)을 사용하였습니다.
#정답보기
for i in range(32):
pred_label = labels[np.argmax(predictions[i])]
fn = fns[i]
la = labels[label[i]]
print(i, '번째', '파일', fn, '참값', la, '예측값', pred_label)
>>>0 번째 파일 ./CIFAR-10-images-master/test/truck/0959.jpg 참값 truck 예측값 truck
>>>1 번째 파일 ./CIFAR-10-images-master/test/truck/0830.jpg 참값 truck 예측값 truck
>>>2 번째 파일 ./CIFAR-10-images-master/test/bird/0134.jpg 참값 bird 예측값 bird
>>>3 번째 파일 ./CIFAR-10-images-master/test/horse/0935.jpg 참값 horse 예측값 horse
>>>4 번째 파일 ./CIFAR-10-images-master/test/horse/0147.jpg 참값 horse 예측값 horse
>>>5 번째 파일 ./CIFAR-10-images-master/test/dog/0239.jpg 참값 dog 예측값 dog
>>>6 번째 파일 ./CIFAR-10-images-master/test/frog/0285.jpg 참값 frog 예측값 frog
>>>7 번째 파일 ./CIFAR-10-images-master/test/truck/0876.jpg 참값 truck 예측값 truck
>>>8 번째 파일 ./CIFAR-10-images-master/test/deer/0236.jpg 참값 deer 예측값 frog
위의 방법이 있다는 수준으로 전달 드린 것입니다. 결국 참값과 예측값을 비교하는 것이죠!!
이번에는 그림으로 시각화 해보시죠!
예측한 데이터와 정답 이미지로 확인 하기
#이미지 데이터를 랜덤하게 n개 추출하여 라벨, 파일이름, 이미지 배열 추출 함수
def load_rand_img(imagesset, randint):
images = imagesset.filepaths
labels = imagesset.labels
rand_imgs = []
label = []
for i in range(randint):
rand_num = random.randrange(0,len(images))
rand_imgs.append(images[rand_num])
label.append(labels[rand_num])
load_imgs = load_img(rand_imgs)
return label, rand_imgs, load_imgs
# 예측 결과를 figure로 확인하는 함수
def plot_predict(figsize, num, classes, label, images, predictions):
fig = plt.figure(figsize=(figsize[0], figsize[1]))
for i in range(num):
plt.subplot(figsize[0], figsize[1], i + 1)
plt.grid(False)
plt.xticks([])
plt.yticks([])
fn = plt.imread(images[i])
plt.imshow(fn)
la = classes[label[i]]
pred_label = classes[np.argmax(predictions[i])]
if pred_label == la:
color = 'green'
else:
color = 'red'
plt.xlabel("{}({}, i={})".format(pred_label, la, i), color=color)
plt.show()
# 메인 실행
labels = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
label, fns, images2 = load_rand_img(images, 10000)
predictions = model.predict(images2/255)
plot_predict((4,8),32, labels, label, fns, predictions)
xlabel의 형식은 "예측값(참값)" 으로 설정하였습니다.
이번 시행에서 32개 중에 7개 오답을 보였으니, 약 22%의 오답률, 즉 78% 정답률을 보여주었지만, 해당 코드는 실행할 때마다 다시 랜덤추출하기 때문에 한눈에 모델을 평가하기는 어렵습니다!!
그래서!! 모델의 성능을 한눈에 보기위해 "Confusion Matrix"를 적용해보았습니다!!
예측한 데이터와 정답을 "Confusion Matrix"로 확인 하기
Confusion Matrix에 대해 잠깐 본다면 참값(타겟의 원래 클래스)와 예측값(모형이 예측한 클래스)가 일치하는지를 갯수로 수치화 한 결과 표라고 보시면 되겠네요!
정답 클래스는 행(row)로, 예측 클래스는 열(column)로 표현하기때문에, Confusion Matrix는 모델이 잘 작동되는지 확인할 수 있는 좋은 방법입니다.
"," 과 ";" 의 구분자들 뒤에 한번의 스페이스 사용을 권장드립니다. (앞에 사용 x)
소괄호, 중괄호, 대괄호 사이에 추가 공백을 사용하지 않도록합니다.
#Correct
spam(ham[1], {eggs: 2})
foo = (0,)
if x == 4: print x, y; x, y = y, x
#Wrong
spam( ham[ 1 ], { eggs: 2 } )
bar = (0, )
if x == 4 : print x , y ; x , y = y , x
03. 주석
03.1. 주석 블록
일반적으로 뒤에 오는 코드 일부나 전체에 대한 내용을 작성합니다.
03.2. 인라인 주석
인라인 주석의 경우 불필요한 경우 사용을 지양합니다.
코드가 명백하지 않을 경우만 사용합니다.
x = x + 1 # Increment x
04. 네이밍
기본적으로 혼란을 주는 문자사용을 지양합니다. (ex 대문자 I와 소문자 L)
04.1. 패키지, 모듈 네이밍
모듈이름은 간결하고 소문자 사용을 권장합니다.
가독성을 위해 "_" (underscores) 사용을 권장합니다.
ex) main.py, main_function.py
04.2. 클래스 네이밍
클래스는 Capitalized 형식(첫자만 대문자)을 권장합니다.
예외처리 또한 클래스와 동일하므로 동일하게 네이밍 하도록 합니다.
ex) MainClass
04.3. 상수, 변수 , 함수, 메서드 네이밍
함수, 변수 (클래스 속성포함), 메소드는 소문자, "_" (underscores) 사용을 권장합니다.
객체란, 어떠한 속성의 값, 행동을 가지는 데이터를 일컫습니다. 파이썬에서 숫자, 문자, 함수 등등 모든 데이터들은 여러 속성과 행동을 가지고 있고 각각이 객체라 볼 수 있습니다.
예시)
세탁기라는 객체는 "빨래를 한다", "빨래 정지한다", "가로 100cm" 등의 속성과 행동으로 표현할 수 있습니다. 이렇든 정의된 데이터가 속성과 행동을 가진다면 객체라고 말할 수 있겠네요!
클래스는 위와 같은 특성을 가지는데요, 왜 그러한지에 대해 차근차근 보겠습니다.
02. 클래스는 복잡한 문제를 다루기 쉽게 한다?
아래의 예시를 통해 이를 확인 할 수 있습니다.
클래스를 통해 복잡하게 반복해야하는 행동을 쉽게 정의하여 해결 할 수 있습니다.
곱셈 계산 기능을 가지는 계산 프로그램 multiply가 있습니다.
이 계산 프로그램은 현재 까지 입력된 모든 숫자들의 곱을 구해야합니다.
예시)
result = 1
def multiply(num):
global result
result *= num
return result
print(multiply(3))
print(multiply(4))
print(multiply(6))
[out]
3
12
72
그런데, 어떠한 상황에서 multiply의 기능을 하는 계산 프로그램이 두개가 필요하다고 생각해봅시다.
예를들어, 1 x 4 x 10 라는 연산과 20 x 4 라는 연산을 한번에 진행해야 할 때, 이러한 상황을 고려해보면 위 와같은 multiply 프로그램을 multiply_1, multiply_2와 같이 두개를 만들어야 합니다.
예시)
result_1 = 1
result_2 = 1
def multiply_1(num):
global result_1
result_1 *= num
return result_1
def multiply_2(num):
global result_2
result_2 *= num
return result_2
print(multiply_1(1))
print(multiply_1(4))
print(multiply_1(10))
print(multiply_2(20))
print(multiply_2(4))
[out]
1
4
40
20
80
좋습니다. 2개까지는 충분히 만들 수 있을거 같습니다. 하지만, 5개, 20개 혹은 그이상이 필요할 때는 어떻게 해야할까요, 하나하나 직접 구현 하는 것은 굉장히 복잡하고, 비효율적입니다.
여기서! 클래스는 이러한 상황을 매우 간단하게 해결합니다!
예시)
#Multiply 클래스 생성
class Multiply:
def __init__(self):
self.result = 1
def multiply(self, num):
self.result *= num
return self.result
# 클래스를 통한 계산기 1
multiply_1 = Multiply()
print("계산기 1 결과")
print(multiply_1.multiply(2))
print(multiply_1.multiply(5))
# 클래스를 통한 계산기 2
multiply_2 = Multiply()
print("계산기 2 결과")
print(multiply_2.multiply(10))
print(multiply_2.multiply(9))
위와 같이 Multiply라는 클래스를 생성하여, multiply_1, multiply_2의 인스턴스를 형성하여 사용할 수 있습니다!
많이 비유되는 거처럼, 클래스는 마치 틀, 공장과 같은 역할을 해서 자신의 형태 결과물인 인스턴스를 만들어냅니다!
3. 객체의 클래스는 초기화를 통해 제어?
클래스를 생성하고 생성된 클래스를 인스턴스로 형성하여 반복적으로 기능을 할 수 있는 것이 클래스의 특징인데요, 여기서 항상 들어가는 "__init__()" 이라는 함수가 있습니다.
이는 생성자라하며, 인스턴스가 생성될때 항상 실행되는 것입니다.
즉, 위의 Multiply라는 클래스를 통해, Multiply_1, Multiply_2 라는 두개의 인스턴스가 생성되었는데요, 생성할때마다 __init__() 함수가 실행되면서 모두 self.result = 1이라는 문장을 실행합니다.
즉, result라는 변수를 인스턴스 형성때마다 초기화가 됩니다. 이러한 장점은 많은 변수를 추가할 필요없게 합니다.
💡메모
클래스에는 생성자와 소멸자라는 개념이 있습니다.
생성자는 위에서 설명한 "__init__()"에 해당되며, 이 생성자를 통해서 객체가 생성될때 어떤 변수의 값을 세팅하는 등 여러가지 작업을 할 수 있습니다.
반면에, "__del__()" 라는 소멸자는 리소스 해제등의 종료 작업을 하기위해 사용됩니다.
#Multiply 클래스 생성
class Multiply:
def __init__(self):
self.result = 1
def multiply(self, num):
self.result *= num
return self.result
#클래스가 인스턴스로 형성될 때마다 __init__() 함수는 실행된다.
#즉 result 인스턴스 형성 마다 개별적으로 초기화
4. 클래스는 객체의 구조와 행동을 정의?
이 특징은 위를 잘 읽으셨다면 충분히 이해 하실 겁니다.
즉, 어떠한 객체에 대해 복잡한 구조를 만들 필요 없이 클래스를 통해서 객체에 대한 행동과 속성을 구조화 시켜 간단하게 해결 할 수 있습니다!!
의사결정 트리 알고리즘은 데이터를 어떤 특징 속에서 연속적으로 분리하여 관측값과 목표값을 연결시켜주는 예측 모델로 사용됩니다.
의사결정 트리의 큰 장점은 이러한 예측모델의 과정을 시각적이고 명시적으로 표현이 가능합니다.
의사결정트리 - 출처: 위키백과
위의 그림과 같이 데이터의 특징 속에서 분류에 큰 영향을 끼치는 특징을 발견하고, 상위노드로 선택하는 알고리즘이 핵심입니다.
💡 여기서 상위노드는 어떤의미일까?
결정 트리에서 질문이나 정답을 담은 모든 박스들을 "노드(Node)"라고 일컫습니다.
또한, 분류 기준(첫 질문)을 Root Node라고 하고, 맨 마지막 노드를 Terminal Node(혹은 Leaf Node) 라고 합니다. 의사 결정트리는 각 노도의 정의한 특징에 따라 아래로 가면서 하단의 노드를 선택하는 알고리즘으로 보이는데 "왜 상위노드" 를 선택한다고 하는지는 의사결정 트리라는 이름이 붙은 이유에서 찾을 수 있습니다.
"Decision Tree"라고 불리는 의사결정 트리는 위의 그림을 전체적인 모양이 나무를 뒤짚어 놓은 것과 같아보이는 것에서 이름이 붙여졌기 때문에 사실상, 상위노드는 Root Node → Terminal Node (Leaf Node)로 가는 방향을 표현 한 것이겠네요!
2.1. 의사결정 트리 알고리즘과 정보 엔트로피의 관계
앞서 말씀드린 것처럼, 의사결정 트리 알고리즘은 각 루트 노드(분류기준)에 따라 스무고개 하듯이 각 노드의 특징을 통해 상위노드를 선택해 나가는 알고리즘입니다. 이런 과정에서 약간씩의 정보를 획득합니다.
정보를 획득한다는 말은 "정답에 대한 불확실성이 줄어든다는 개념" 입니다.
해당 개념을 "정보 이론"에서 불리는 "엔트로피"의 개념을 차용하여 부릅니다.
정보의 획들을 정보 이득이라고 합니다. 아래의 식이 성립합니다.
정보이득에 대한 엔트로피 관점의 수식
💡 질문 후 정보 이득 = 질문 전의 엔트로피 - 질문 후의 엔트로피 즉, 의사결정 트리 알고리즘은 엔트로피가 낮아지는 방향으로 노드가 나아가는 것이겠네요!
즉, 정보의 획등이 최대화하는 방향으로 학습이 진행된다는 것이구요!
💡 정보의 획득이 정답에 대한 불확실성을 줄인다는 것을 이해했는데, 이게 정보이론의 "엔트로피"와 무슨 상관일까??
간단하게 말해서, 정보이론의 엔트로피는 "무질서함"을 이야기하고 이는 "불확실성"에 대한 개념을 내포하고 있습니다. 이를테면, 마음먹고 정리한 내 책상은 이틀 뒤에 지저분해져있습니다.